索引與 B+ Tree
深入 InnoDB 的 B+ Tree 索引結構、Clustered Index 與 Secondary Index 的差異、覆蓋索引、索引下推、常見索引優化策略
為什麼是 B+ Tree
資料庫索引的核心問題是:怎麼在最少的磁碟 IO 次數內找到目標行。InnoDB 選了 B+ Tree,原因有三:
- 矮胖:每個節點可以裝很多 key。16KB 的頁、8 bytes 的 bigint key + 6 bytes pointer,一個非葉節點能放約 1170 個 key。三層 B+ Tree 就能索引 1170 × 1170 × 16 ≈ 兩千萬行,只需要 3 次磁碟 IO。
- 葉節點有序鏈表:B+ Tree 的葉節點用雙向鏈表串起來,範圍查詢只要定位起點後順著鏈表走,對排序與
BETWEEN極度友好。 - 穩定:所有查詢都走到葉節點,查詢效能一致(不像 B Tree 可能在內部節點就命中)。
相較之下,Hash Index 只能做等值查詢不能範圍查詢,AVL/紅黑樹太高磁碟 IO 多。
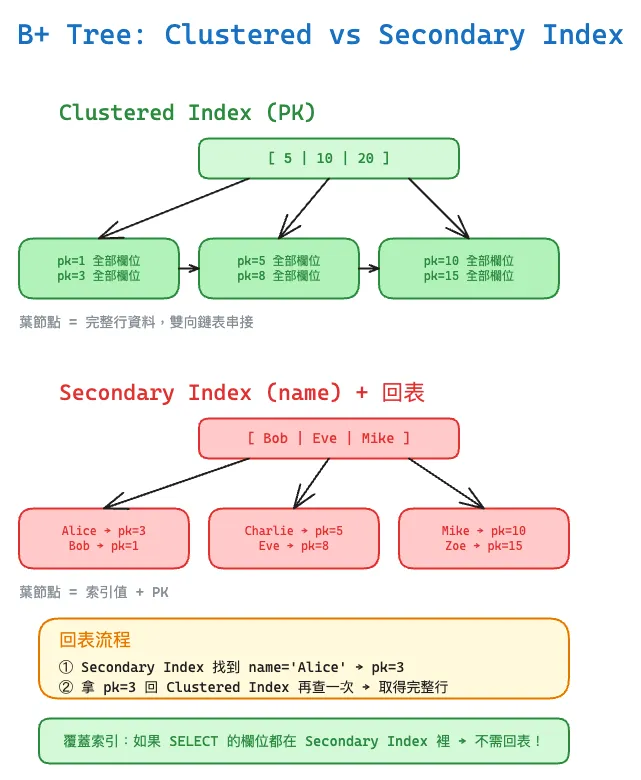
Clustered Index(聚簇索引)
InnoDB 的資料就存在 Clustered Index 的葉節點上。換句話說,Clustered Index 就是資料本身的物理組織方式。
選擇順序:
- 有 PRIMARY KEY → 用 PK 當 Clustered Index
- 沒有 PK 但有 NOT NULL UNIQUE → 用第一個這樣的欄位
- 都沒有 → InnoDB 自動生成隱藏的
DB_ROW_ID(6 bytes 自增)
Clustered Index 的葉節點存的是完整的行資料。所以用 PK 查詢只需要一次 B+ Tree 查找就能拿到所有欄位——這也是為什麼建議主鍵用自增 bigint 而非 UUID。
為什麼主鍵建議用自增
自增主鍵的 INSERT 永遠在 B+ Tree 最右邊追加,頁面順序填滿,不會引起頁分裂。UUID 或隨機值主鍵的 INSERT 會散落在各個位置,頻繁觸發頁分裂(一個頁分成兩個半滿的頁),導致空間浪費和額外 IO。
| 主鍵類型 | INSERT 行為 | 頁分裂 | 空間利用率 | 查詢效能 |
|---|---|---|---|---|
| 自增 bigint | 順序追加 | 極少 | 高 | 範圍查詢友好 |
| UUID (CHAR 36) | 隨機插入 | 頻繁 | ~50% | 索引更大 |
| UUID binary(16) | 隨機插入 | 頻繁 | 較好 | 索引小但仍隨機 |
| 有序 UUID (v7) | 近似順序追加 | 少 | 高 | 接近自增 |
Secondary Index(二級索引)
Clustered Index 以外的索引都是 Secondary Index。它的葉節點存的不是整行資料,而是索引欄位的值 + 主鍵值。
Secondary Index (idx_name)
葉節點: [name='Alice', pk=1] → [name='Bob', pk=3] → [name='Charlie', pk=2]
Clustered Index
葉節點: [pk=1, 完整行] → [pk=2, 完整行] → [pk=3, 完整行]
回表(Back to Clustered Index)
用 Secondary Index 查詢的流程:
- 在 Secondary Index 的 B+ Tree 找到符合條件的葉節點,拿到主鍵值
- 拿主鍵值去 Clustered Index 的 B+ Tree 再查一次,拿到完整行資料
這第二步就是回表。一次 Secondary Index 查詢 = 一次 Secondary B+ Tree 走訪 + N 次 Clustered B+ Tree 走訪(N = 符合條件的行數)。回表次數多時比全表掃描還慢——這就是為什麼 optimizer 有時會放棄索引選擇全表掃描。
覆蓋索引(Covering Index)
如果 Secondary Index 包含了查詢需要的所有欄位,就不需要回表。這叫覆蓋索引。
-- 假設有索引 idx_name_age (name, age)
SELECT name, age FROM users WHERE name = 'Alice';
-- EXPLAIN 的 Extra 會顯示 "Using index",代表覆蓋索引命中,不需要回表
設計複合索引時把常查的欄位包進去,讓更多查詢能走覆蓋索引,是最常見也最有效的索引優化。
複合索引(Composite Index)與最左前綴
複合索引 (a, b, c) 在 B+ Tree 中的排序規則是:先按 a 排,a 相同按 b 排,b 相同按 c 排。
這決定了哪些查詢能用到這個索引:
| 查詢條件 | 是否能用索引 | 用到幾個欄位 |
|---|---|---|
WHERE a = 1 | ○ | a |
WHERE a = 1 AND b = 2 | ○ | a, b |
WHERE a = 1 AND b = 2 AND c = 3 | ○ | a, b, c |
WHERE b = 2 | × | 無(跳過 a) |
WHERE a = 1 AND c = 3 | △ | 只有 a(c 無法跳過 b 用索引) |
WHERE a > 1 AND b = 2 | △ | a(範圍查詢後索引中斷) |
WHERE a = 1 ORDER BY b | ○ | a 定位 + b 排序 |
最左前綴原則:查詢必須從索引最左邊的欄位開始、不能跳過中間欄位,遇到範圍查詢(>、<、BETWEEN、LIKE ‘abc%‘)後面的欄位就無法再用索引過濾(但在 8.0 中可透過 Index Condition Pushdown 在 engine 層過濾,減少回表)。
索引設計順序
建複合索引時欄位的擺放順序很重要:
- 等值查詢的欄位放前面:等值條件能精確定位到 B+ Tree 的一段連續範圍
- 範圍查詢的欄位放後面:範圍條件之後的欄位無法走索引
- 排序欄位也考慮:如果 ORDER BY 能利用索引順序就省掉 filesort
索引下推(Index Condition Pushdown, ICP)
MySQL 5.6 引入。沒有 ICP 時,Server 層從 Storage Engine 拿到符合索引前幾個欄位的行後,自己再過濾後面的條件。有 ICP 時,Storage Engine 在索引層就先過濾,減少回表次數。
-- 索引 idx_name_age (name, age)
SELECT * FROM users WHERE name LIKE 'A%' AND age = 25;
沒有 ICP:InnoDB 回傳所有 name 以 A 開頭的行(可能 1000 行),Server 層再過濾 age=25。 有 ICP:InnoDB 在索引層就先檢查 age=25,只回傳同時滿足的行(可能只有 10 行)。
EXPLAIN 的 Extra 顯示 Using index condition 代表 ICP 生效。
索引失效的常見情況
| 情況 | 原因 | 解法 |
|---|---|---|
對欄位做函數 WHERE YEAR(date)=2026 | 索引存的是原始值,函數結果沒有索引 | 改成 WHERE date >= '2026-01-01' AND date < '2027-01-01' |
隱式型別轉換 WHERE varchar_col = 123 | MySQL 把 varchar 轉 int 等於對每行做函數 | 確保型別一致 |
| LIKE ‘%abc’ | 前綴未知,無法定位 B+ Tree 起點 | 改成 LIKE 'abc%' 或全文索引 |
| OR 連接非索引欄位 | 有一邊沒索引就全表掃描 | 拆成 UNION 或補索引 |
| NOT IN / != | 無法利用索引的有序性 | 看情況改寫或接受 |
索引的代價
索引不是免費的:
- 空間:每個 Secondary Index 都是一棵完整的 B+ Tree。索引多的表,索引大小可能超過資料本身。
- 寫入:每次 INSERT / UPDATE / DELETE 都要同步維護所有相關索引。5 個索引的 INSERT 就是 5 次 B+ Tree 修改(可能觸發頁分裂)。
- Optimizer 負擔:索引太多,optimizer 選錯索引的機率增加。
生產環境建議單表索引不超過 5–6 個,每個索引不超過 3–4 個欄位。過多索引要定期用 sys.schema_unused_indexes 清理。
常用索引診斷
-- 查看表的索引
SHOW INDEX FROM table_name;
-- 分析查詢是否走索引
EXPLAIN SELECT ...;
EXPLAIN ANALYZE SELECT ...; -- 8.0.18+ 真正執行並顯示實際 row 數
-- 未使用的索引(需開啟 performance_schema)
SELECT * FROM sys.schema_unused_indexes;
-- 索引的 cardinality(區分度)
SELECT
index_name, column_name, cardinality
FROM information_schema.statistics
WHERE table_schema = 'your_db' AND table_name = 'your_table';
Cardinality 越高代表區分度越好。性別欄位(只有 M/F)的 cardinality 極低,建索引效果差;身份證號的 cardinality 最高,是理想的索引候選。