InnoDB 鎖機制
深入解析 InnoDB 的各種鎖類型——Record Lock、Gap Lock、Next-Key Lock、Insert Intention Lock、Metadata Lock、隱式鎖,以及死鎖的成因與排查
鎖的層級
InnoDB 的鎖橫跨三個層級:Server 層的 Metadata Lock、表級鎖(Intention Lock、AUTO-INC Lock)、行級鎖(Record Lock、Gap Lock、Next-Key Lock、Insert Intention Lock)。此外還有不產生鎖結構的隱式鎖(Implicit Lock)。
| 層級 | 鎖類型 | 加鎖單位 |
|---|---|---|
| Server 層 | Metadata Lock(MDL) | 表的元資料 |
| 表級 | Table Lock、Intention Lock、AUTO-INC Lock | 整張表 |
| 行級 | Record Lock、Gap Lock、Next-Key Lock、Insert Intention Lock | 索引記錄或間隙 |
InnoDB 的行鎖是鎖在索引上的,不是鎖在行資料上。如果查詢走不了索引(全表掃描),InnoDB 會鎖住 Clustered Index 的每一筆記錄,效果等同表鎖。
共享鎖與排他鎖
| 鎖 | 簡寫 | 語意 | 相容性 |
|---|---|---|---|
| 共享鎖 | S | 允許讀,不允許寫 | S 與 S 相容 |
| 排他鎖 | X | 不允許讀也不允許寫 | X 與任何鎖互斥 |
注意:這裡的「讀」是指當前讀(SELECT ... FOR SHARE),不是快照讀。普通 SELECT 走 MVCC,完全不加鎖,與 S/X lock 沒有衝突。
-- 共享鎖(S lock)
SELECT * FROM orders WHERE id = 1 FOR SHARE; -- 8.0+
SELECT * FROM orders WHERE id = 1 LOCK IN SHARE MODE; -- 舊語法
-- 排他鎖(X lock)
SELECT * FROM orders WHERE id = 1 FOR UPDATE;
-- UPDATE / DELETE 自動加 X lock
意向鎖(Intention Lock)
表級鎖。InnoDB 在對行加 S/X lock 之前,會先在表上加對應的 IS/IX lock。目的是讓表級鎖的檢查更快:
| 鎖 | 意義 |
|---|---|
| IS | 交易打算對某些行加 S lock |
| IX | 交易打算對某些行加 X lock |
意向鎖之間不互斥(IS 與 IX 相容),只和表級 S/X lock 互斥。舉例:LOCK TABLES t WRITE 需要表級 X lock,但如果有人已經對某行加了 X lock(表上有 IX),就會被阻塞——不需要逐行檢查。
Record Lock

鎖住索引記錄本身。只鎖一個精確的值。
觸發條件:唯一索引 + 等值查詢 + 記錄存在。這是 Next-Key Lock 的退化形式——唯一索引命中唯一記錄時,不需要鎖 gap,因為唯一性本身就保證不會有其他行插入。
-- 假設 id 是主鍵
SELECT * FROM orders WHERE id = 1 FOR UPDATE;
-- 只鎖 id=1 這筆記錄,其他行不受影響
在 Read Committed 下,InnoDB 只使用 Record Lock(沒有 gap lock)。
Gap Lock
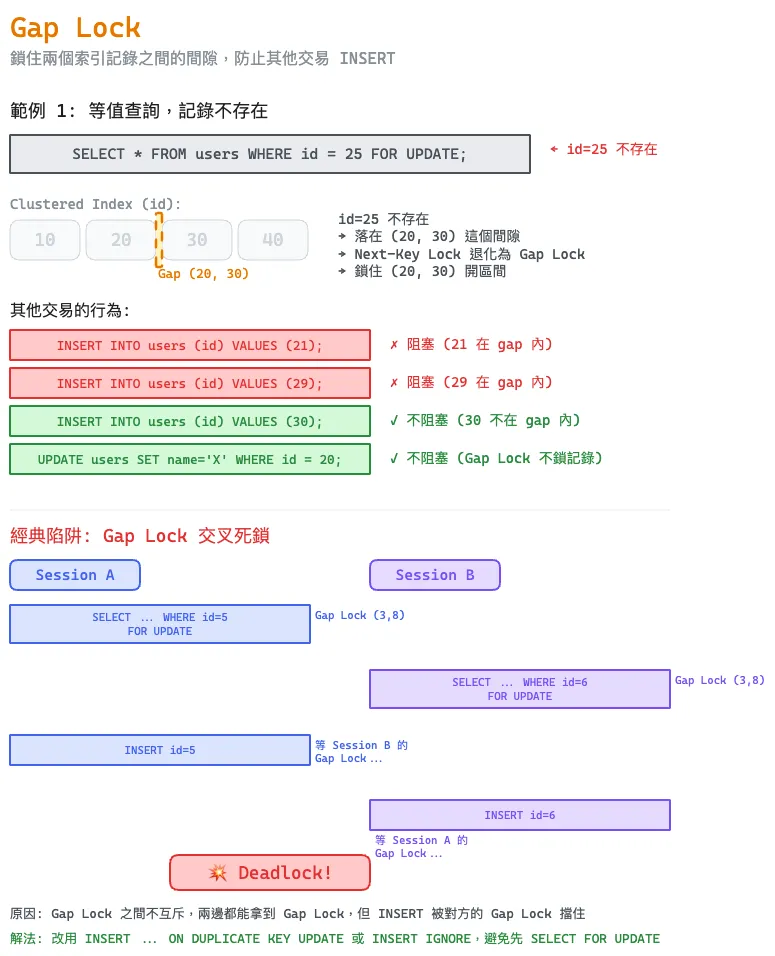
鎖住兩個索引記錄之間的間隙,但不包含記錄本身。目的是防止其他交易在這個間隙 INSERT 新行——防幻讀。
觸發條件:等值查詢 + 記錄不存在(RR 隔離等級)。這也是 Next-Key Lock 的退化形式——查詢的記錄不存在時,不需要鎖記錄本身(根本沒有記錄),只需要鎖住間隙防止 INSERT。
索引記錄: 10, 20, 30
Gap: (-∞,10) (10,20) (20,30) (30,+∞)
-- 假設 id 是主鍵,且目前有 id=10, 20, 30 的記錄
SELECT * FROM users WHERE id = 25 FOR UPDATE;
-- id=25 不存在,InnoDB 鎖住 (20, 30) 這個 gap
-- 其他交易不能在這個範圍內 INSERT
-- 但 UPDATE id=20 或 UPDATE id=30 不受影響(Gap Lock 不鎖記錄)
Gap lock 只在 Repeatable Read 以上存在。Read Committed 下不加 gap lock,所以 RC 不防幻讀但死鎖風險低。
Gap lock 之間不互斥——兩個交易可以同時持有同一個 gap lock。Gap lock 唯一擋住的是 INSERT。這個特性是 Gap Lock 交叉死鎖的根源(見下方死鎖段落)。
Next-Key Lock

Record Lock + Gap Lock 的組合,鎖住索引記錄本身加上這個記錄前面的間隙。形式是左開右閉區間 (prev_record, current_record]。
觸發條件:非唯一索引查詢,或範圍查詢(RR 隔離等級)。這是 InnoDB 在 RR 下的預設鎖行為——每次當前讀掃過索引記錄時,都會對掃過的記錄加 Next-Key Lock,只有在特定條件下才退化為 Record Lock 或 Gap Lock。
索引記錄: 10, 20, 30
Next-Key Locks: (-∞,10] (10,20] (20,30] (30,+∞)
加鎖規則(RR 下)
InnoDB 的加鎖過程比較複雜,但有幾條核心規則:
- 掃描索引時,對每個訪問到的索引記錄加 Next-Key Lock
- 如果是等值查詢且命中唯一索引的唯一記錄,Next-Key Lock 退化為 Record Lock(不需要鎖 gap,因為唯一性保證不會有其他行)
- 如果是等值查詢但記錄不存在,Next-Key Lock 退化為 Gap Lock
- 如果走的是 Secondary Index,找到記錄後還會對 Clustered Index 的對應記錄加 Record Lock
範例(含 InnoDB 掃描加鎖過程)
假設有表 t(id PK, age KEY),資料:(1,10), (5,20), (8,20), (12,30)
Secondary Index age 上的索引記錄順序(按 age 排序,相同 age 按 id 排序):
age=10 (id=1) → age=20 (id=5) → age=20 (id=8) → age=30 (id=12)
Case 1: 唯一索引等值命中
SELECT * FROM t WHERE id = 5 FOR UPDATE;
掃描過程:在 Clustered Index 上精確找到 id=5。
加鎖結果:id=5 Record Lock(退化:唯一索引命中唯一記錄 → 不需要鎖 gap)。
Case 2: 唯一索引等值未命中
SELECT * FROM t WHERE id = 7 FOR UPDATE;
掃描過程:在 Clustered Index 上找 id=7,找不到,定位到下一條記錄 id=8。
加鎖結果:(5, 8) Gap Lock(退化:記錄不存在 → 不需要鎖記錄本身,只鎖 gap 防止 INSERT)。
Case 3: 非唯一索引等值查詢(最重要的 case)
SELECT * FROM t WHERE age = 20 FOR UPDATE;
InnoDB 在 Secondary Index age 上的掃描過程,逐步加鎖:
-
定位到第一條 age=20 的記錄(id=5)
- 加 Next-Key Lock:
(10, 20](鎖住 age=10 到 age=20(id=5) 的間隙 + age=20(id=5) 記錄) - 同時回 Clustered Index 對
id=5加 Record Lock
- 加 Next-Key Lock:
-
繼續掃描到第二條 age=20 的記錄(id=8)
- 加 Next-Key Lock:
(20(id=5), 20(id=8)](兩條 age=20 之間的間隙 + age=20(id=8) 記錄) - 同時回 Clustered Index 對
id=8加 Record Lock
- 加 Next-Key Lock:
-
繼續掃描到下一條記錄 age=30(id=12)——不符合 age=20 的條件,到此為止
- 但 InnoDB 是「掃到不符合才停」,所以在停下之前已經訪問了 age=30 這條記錄
- 本來要加
(20(id=8), 30]Next-Key Lock - 等值查詢的最後一條不匹配記錄,Next-Key Lock 退化為 Gap Lock:
(20(id=8), 30) - age=30 記錄本身不被鎖,只鎖間隙
最終鎖的範圍:
- Secondary Index:
(10, 20]Next-Key +(20(id=8), 30)Gap Lock → age=10 到 age=30 之間的所有 INSERT 都被阻擋 - Clustered Index:
id=5Record Lock +id=8Record Lock
為什麼要鎖這麼大的範圍?因為 age 不是唯一索引,任何人都可能 INSERT 一筆新的 age=20 行。如果不鎖前後的 gap,新插入的 age=20 就會被遺漏(幻讀)。
Case 4: 範圍查詢
SELECT * FROM t WHERE age >= 20 AND age < 25 FOR UPDATE;
掃描過程和 Case 3 類似,但範圍更大:
- 掃描到 age=20 (id=5):加
(10, 20]Next-Key Lock → 回表加id=5Record Lock - 掃描到 age=20 (id=8):加
(20(id=5), 20(id=8)]Next-Key Lock → 回表加id=8Record Lock - 掃描到 age=30 (id=12):
age=30 >= 25,不在條件範圍,掃描停止- 但 InnoDB 已經訪問了這條記錄才知道可以停,所以加
(20(id=8), 30]Next-Key Lock - 範圍查詢的最後一條不退化(和等值查詢不同)→ age=30 記錄也被鎖住了
- 但 InnoDB 已經訪問了這條記錄才知道可以停,所以加
這是 InnoDB 鎖機制中最常踩坑的地方:age < 25 的查詢條件,卻把 age=30 的記錄也鎖了。原因是 InnoDB 沒有「精確範圍」的概念——它只知道「我掃到這條記錄才發現不符合條件」,但鎖已經加了。
Insert Intention Lock(插入意向鎖)
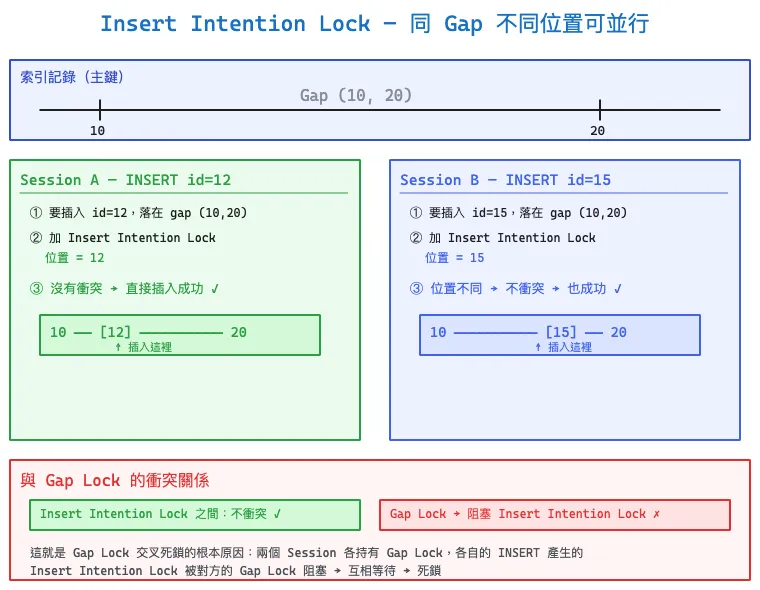
Insert Intention Lock 是一種特殊的 Gap Lock,但行為和普通 Gap Lock 完全相反——它不是為了阻擋 INSERT,而是 INSERT 本身在等待 gap 時所加的鎖。
為什麼需要它?
如果沒有 Insert Intention Lock,同一個 gap 內的多個 INSERT 就得互相等待。但實際上,只要插入的位置不同,就沒有衝突。Insert Intention Lock 的設計就是:同一個 gap 內,不同位置的 INSERT 可以並行。
範例
假設索引記錄有 10 和 20,中間的 gap 是 (10, 20):
-- Session A
BEGIN;
INSERT INTO t VALUES (12, ...);
-- 在 gap (10, 20) 加 Insert Intention Lock,位置 = 12
-- 沒人擋 → 直接成功
-- Session B
BEGIN;
INSERT INTO t VALUES (15, ...);
-- 在 gap (10, 20) 加 Insert Intention Lock,位置 = 15
-- 與 Session A 的位置不同 → 不衝突 → 也直接成功
兩個 INSERT 在同一個 gap 裡但位置不同,可以同時執行,不需要等待。
與 Gap Lock 的互動(死鎖根源)
Insert Intention Lock 會被普通 Gap Lock 阻塞。這正是前面 Gap Lock 交叉死鎖的完整機制:
Session A: 持有 Gap Lock (3,8) → Session B INSERT id=6 的 Insert Intention Lock 被擋
Session B: 持有 Gap Lock (3,8) → Session A INSERT id=5 的 Insert Intention Lock 被擋
→ 死鎖
關鍵區別:普通 Gap Lock 之間不互斥,但 Gap Lock 會阻塞 Insert Intention Lock。
Metadata Lock(MDL)

MDL 是 Server 層(不是 InnoDB 層)的鎖,用來協調 DDL(ALTER TABLE、DROP TABLE)和 DML(SELECT、UPDATE)。MySQL 5.5 引入,解決的是 DDL 和 DML 併發時的元資料一致性問題。
加鎖規則
| 操作 | MDL 類型 | 說明 |
|---|---|---|
| SELECT / DML | MDL 讀鎖(SHARED_READ / SHARED_WRITE) | 語句結束或交易結束時釋放 |
| ALTER TABLE / DROP TABLE | MDL 寫鎖(EXCLUSIVE) | 與所有 MDL 讀鎖互斥 |
MDL 讀鎖之間相容(多個 SELECT 可並行),但 MDL 寫鎖與一切互斥。
生產踩坑:一條 ALTER TABLE 卡住全部查詢
這是最常見的 MDL 事故:
-- ① 長交易(Session A)正在跑,持有 MDL 讀鎖
BEGIN;
SELECT * FROM users WHERE id = 1; -- MDL 讀鎖,交易未提交 → 不釋放
-- ② DBA 執行 ALTER TABLE(Session B)
ALTER TABLE users ADD COLUMN age INT;
-- 需要 MDL 寫鎖 → 被 Session A 的 MDL 讀鎖擋住 → 排隊等待
-- ③ 之後所有新查詢(Session C, D, E...)
SELECT * FROM users WHERE id = 2;
-- 需要 MDL 讀鎖,但 MDL 寫鎖的等待優先級更高
-- → 排在 ALTER TABLE 後面 → 全部阻塞!
一個未提交的長交易 + 一條 ALTER TABLE = 表完全不可用。問題不是 ALTER TABLE 本身慢,而是它在等待的過程中阻塞了所有後續的讀寫。
排查與預防
-- 查看 MDL 鎖等待
SELECT * FROM performance_schema.metadata_locks;
-- 找出阻塞源頭
SELECT * FROM sys.schema_table_lock_waits;
-- 找長交易
SELECT * FROM information_schema.innodb_trx
ORDER BY trx_started ASC LIMIT 5;
預防措施:避免長交易(特別是不要在交易中做完查詢後去喝咖啡)、DDL 操作前先確認沒有長時間持有 MDL 的交易、使用 pt-online-schema-change 或 MySQL 8.0 的 INSTANT DDL 減少 DDL 持鎖時間。
隱式鎖(Implicit Lock)
InnoDB 的一項效能優化:INSERT 時不立刻建立顯式的鎖結構,而是利用記錄上的 DB_TRX_ID(隱藏的交易 ID 欄位)來實現「隱式」的排他鎖。
運作機制
- Session A 執行 INSERT,新記錄的
DB_TRX_ID= Session A 的交易 ID - 此時 InnoDB 不建立任何鎖結構(省記憶體、省 CPU)
- Session B 想讀或修改這筆記錄 → 檢查
DB_TRX_ID→ 發現是活躍交易 → 此時才把隱式鎖轉換為顯式 X lock - Session B 進入等待
為什麼這樣設計?
大部分 INSERT 之後不會立刻有衝突。如果每次 INSERT 都建立鎖結構,多數鎖結構最終用不到就被釋放了——浪費資源。延遲到有衝突時才建立,是典型的 lazy evaluation 策略。
對 Secondary Index 也有類似的機制:InnoDB 透過 Page 上的 max trx id 判斷是否需要做隱式鎖轉換。
AUTO-INC Lock
用於自增欄位。InnoDB 有三種模式(innodb_autoinc_lock_mode):
| 值 | 模式 | 行為 | 適用 |
|---|---|---|---|
| 0 | Traditional | 表級 AUTO-INC lock,語句結束才釋放 | 已過時 |
| 1 | Consecutive | 簡單 INSERT 用輕量 mutex;bulk INSERT 用表級鎖 | 5.7 預設 |
| 2 | Interleaved | 全部用輕量 mutex,自增值可能不連續 | 8.0 預設 |
Mode 2 效能最好但自增值可能有空洞(兩個併發 INSERT 各拿一段)。搭配 ROW 格式 binlog 不影響主從一致。STATEMENT 格式 binlog 需要 mode 0 或 1 才安全。
死鎖
兩個(或多個)交易互相等待對方持有的鎖,永遠無法推進。
經典場景:相反順序更新
-- Session A
BEGIN;
UPDATE accounts SET balance = 100 WHERE id = 1; -- 鎖 id=1
-- Session B
BEGIN;
UPDATE accounts SET balance = 200 WHERE id = 2; -- 鎖 id=2
-- Session A
UPDATE accounts SET balance = 300 WHERE id = 2; -- 等 id=2 → 等 Session B
-- Session B
UPDATE accounts SET balance = 400 WHERE id = 1; -- 等 id=1 → 等 Session A → 死鎖!
Gap Lock 交叉死鎖
-- Session A
BEGIN;
SELECT * FROM orders WHERE id = 5 FOR UPDATE; -- id=5 不存在,加 Gap Lock (3, 8)
-- Session B
BEGIN;
SELECT * FROM orders WHERE id = 6 FOR UPDATE; -- id=6 不存在,加 Gap Lock (3, 8)
-- Gap Lock 不互斥,兩邊都能拿到
-- Session A
INSERT INTO orders (id) VALUES (5); -- 被 Session B 的 Gap Lock 擋住
-- Session B
INSERT INTO orders (id) VALUES (6); -- 被 Session A 的 Gap Lock 擋住 → 死鎖!
這在「先 SELECT 確認不存在再 INSERT」的業務邏輯中很常見。解法:改用 INSERT ... ON DUPLICATE KEY UPDATE 或 INSERT IGNORE,避免先 SELECT FOR UPDATE。
InnoDB 的死鎖處理
InnoDB 有 wait-for graph 偵測死鎖。發現環路後立刻回滾其中一個交易(通常是 undo log 最少的),另一個繼續。被回滾的交易收到 ERROR 1213 (40001): Deadlock found。
-- 查看最近的死鎖資訊
SHOW ENGINE INNODB STATUS\G
-- 找 "LATEST DETECTED DEADLOCK" 段落
-- 開啟死鎖日誌記錄所有死鎖(慎用,量大)
SET GLOBAL innodb_print_all_deadlocks = ON;
減少死鎖的實務建議
- 固定加鎖順序:所有交易按相同順序存取資源(如按 id 遞增)
- 縮短交易:持鎖時間越短碰撞概率越低
- 避免大範圍鎖:精確的 WHERE 條件、走索引,減少鎖的範圍
- 用 RC 隔離等級:沒有 gap lock,死鎖概率大幅降低
- 重試機制:死鎖不可完全避免,應用層要有 retry 邏輯
鎖的監控
-- 查看當前持有的鎖
SELECT * FROM performance_schema.data_locks;
-- 查看鎖等待
SELECT * FROM performance_schema.data_lock_waits;
-- 查看正在跑的交易
SELECT * FROM information_schema.innodb_trx;
-- 等待超時設定(預設 50 秒)
SHOW VARIABLES LIKE 'innodb_lock_wait_timeout';
鎖與隔離等級的關係總結
| 隔離等級 | 快照讀 | 當前讀的鎖行為 |
|---|---|---|
| Read Uncommitted | 不用 MVCC | Record Lock |
| Read Committed | MVCC | Record Lock(無 Gap Lock) |
| Repeatable Read | MVCC | Next-Key Lock(Record + Gap) |
| Serializable | 不用 MVCC | 所有 SELECT 自動加 S lock + Next-Key Lock |
RC 少了 gap lock 所以死鎖少、併發高,但犧牲了幻讀防護。RR 用 Next-Key Lock 防幻讀但鎖範圍大、死鎖風險高。沒有完美的選擇,只有 trade-off。