MySQL 架構總覽
介紹 MySQL 的分層架構:Server Layer 與 Storage Engine Layer,以及 InnoDB 為何成為預設引擎
分層架構
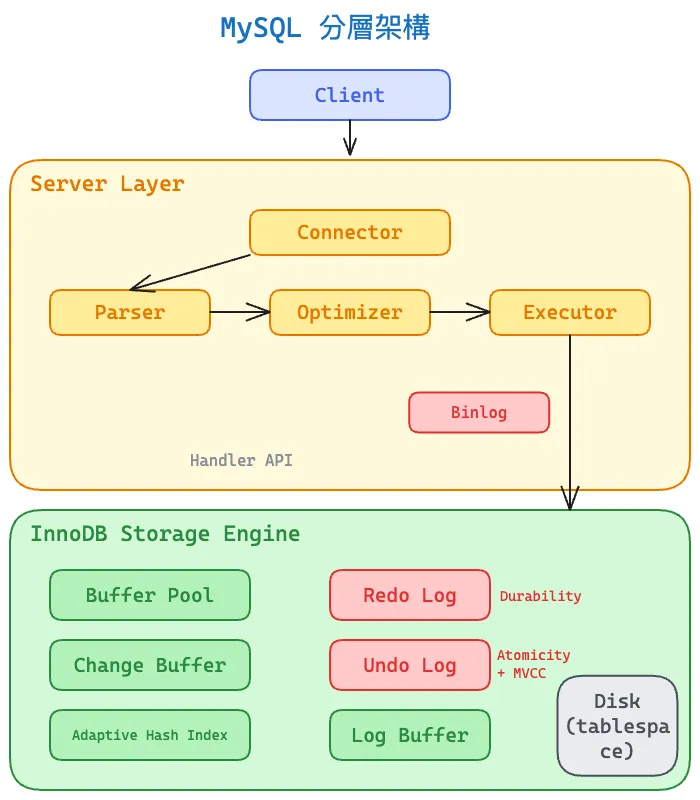
MySQL 的架構可分為兩大層:Server Layer 與 Storage Engine Layer。所有 SQL 解析、優化、權限控制在 Server Layer 完成;資料怎麼存、怎麼讀、怎麼保證一致性全由 Storage Engine 決定。兩層之間透過統一的 Handler API 溝通,這也是 MySQL 能支援多種引擎的原因。
Server Layer
一條 SQL 從客戶端進來到拿到結果,在 Server Layer 會依序經過:
- Connector:管理連線、驗證帳號密碼、取得權限。每個連線對應一個 thread(或 thread pool 中的一個 worker)。長連線佔記憶體,生產環境通常搭配連線池(HikariCP、ProxySQL)。
- Query Cache(8.0 已移除):以 SQL 文字為 key 快取結果。命中率極低且任何寫入都會 invalidate 整張表的快取,8.0 正式移除。
- Parser:詞法分析 + 語法分析,產出 AST(Abstract Syntax Tree)。語法錯誤在這一步報出。
- Optimizer:根據統計資訊(index cardinality、表大小)決定執行計畫——用哪個索引、join 順序、是否用覆蓋索引。
EXPLAIN看到的就是 optimizer 的輸出。 - Executor:按 optimizer 的計畫呼叫 Storage Engine 的 Handler API 取資料,組裝結果集回傳客戶端。
Storage Engine Layer
MySQL 的引擎是可插拔的,但生產環境幾乎只用 InnoDB(5.5 起成為預設)。
| 引擎 | 交易支援 | 鎖粒度 | 適用場景 |
|---|---|---|---|
| InnoDB | ○ | Row | OLTP、幾乎所有場景 |
| MyISAM | × | Table | 歷史遺留,不推薦 |
| Memory | × | Table | 臨時表、快取 |
| Archive | × | Row | 日誌歸檔 |
不用 MyISAM 的理由:不支援交易、不支援 row lock、crash 後無法自動復原。
InnoDB 核心元件
Buffer Pool
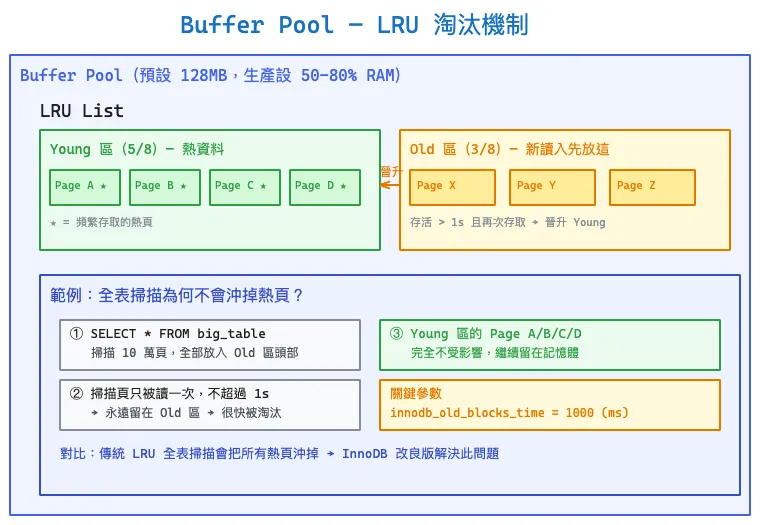
InnoDB 最重要的記憶體結構。所有資料頁(data page, 16KB)讀寫都先經過 Buffer Pool,避免每次都碰磁碟。預設大小 128MB,生產環境通常設為實體記憶體的 50–80%。
改良版 LRU 淘汰機制
傳統 LRU 的問題是:一次全表掃描就會把所有熱頁沖出快取。InnoDB 把 LRU list 分成 Young 區(5/8) 和 Old 區(3/8) 兩段來解決:
- 新讀入的頁先放入 Old 區頭部,而非直接進入 Young 區
- 只有在 Old 區存活超過
innodb_old_blocks_time(預設 1000ms)且再次被存取,才晉升到 Young 區 - Young 區存放真正的熱資料(頻繁存取的頁),不會被一次性操作沖掉
範例:全表掃描為何不會沖掉熱頁?
假設執行 SELECT * FROM big_table 掃描 10 萬頁:
- 掃描過程中,這些頁全部進入 Old 區頭部
- 掃描頁只被讀一次,不會在 Old 區停留超過 1 秒,也不會再次被存取
- 因此掃描頁永遠無法晉升到 Young 區,很快就被淘汰
- Young 區的 Page A、B、C、D 等熱頁完全不受影響,繼續留在記憶體
如果用傳統 LRU,這 10 萬個掃描頁會直接把 Young 區的熱頁全部擠出去,之後正常查詢的 cache miss 會暴增,這就是所謂的 Buffer Pool 污染。
Change Buffer
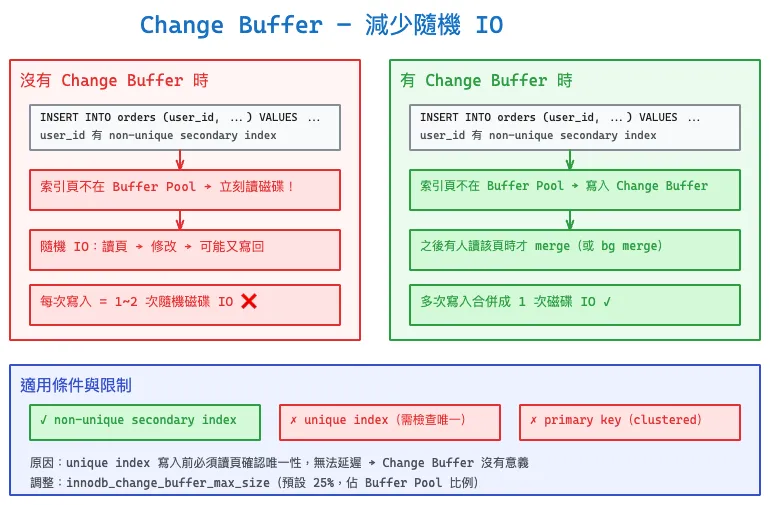
當對 non-unique secondary index 執行寫入(INSERT/UPDATE/DELETE),如果目標索引頁不在 Buffer Pool 中,正常流程是:從磁碟讀頁 → 修改 → 寫回,這會產生大量隨機 IO。
沒有 Change Buffer 時
以 INSERT INTO orders (user_id, ...) VALUES (...) 為例,user_id 上有 non-unique secondary index:
- 索引頁不在 Buffer Pool → 立刻從磁碟讀頁(隨機 IO)
- 在記憶體中修改索引頁
- 每次寫入 = 1~2 次隨機磁碟 IO,高併發寫入時效能瓶頸明顯
有 Change Buffer 時
同樣的 INSERT:
- 索引頁不在 Buffer Pool → 把變更暫存到 Change Buffer(記憶體操作,極快)
- 不需要立刻讀磁碟,等到之後有人讀該索引頁時才 merge
- 多次寫入可以合併成一次磁碟 IO,對寫多讀少的場景效果明顯
適用條件與限制
Change Buffer 只能用於 non-unique secondary index,不適用於:
- Unique index:寫入前必須讀頁確認唯一性約束,無法延遲讀取,Change Buffer 沒意義
- Primary key(clustered index):同理需要檢查主鍵衝突
調整佔用空間:innodb_change_buffer_max_size(預設 25,表示最多佔 Buffer Pool 的 25%)。
Adaptive Hash Index
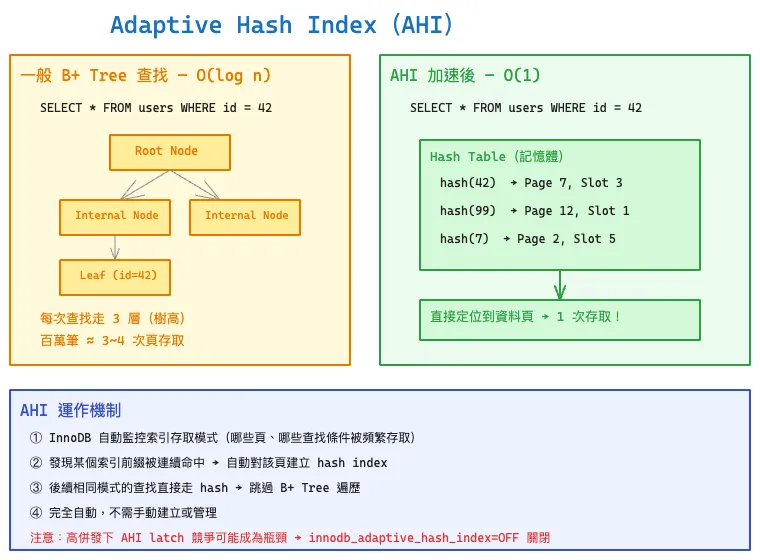
B+ Tree 索引的查找時間複雜度是 O(log n),以百萬筆資料來說大約要 3~4 次頁存取(走 Root → Internal → Leaf)。如果某些查詢模式被大量重複執行,這些重複的樹遍歷就成了浪費。
AHI 如何加速?
InnoDB 在記憶體中維護一個 hash table,把特定索引前綴直接映射到資料頁位置:
- InnoDB 自動監控索引存取模式——哪些頁、哪些查找條件被頻繁存取
- 發現某個索引前綴被連續命中(例如
WHERE id = ?被大量查詢)→ 自動對該頁建立 hash index - 後續相同模式的查找直接走 hash → O(1) 定位到資料頁,跳過 B+ Tree 遍歷
- 完全自動,不需手動建立或管理
範例對比
以 SELECT * FROM users WHERE id = 42 為例:
- 沒有 AHI:Root Node → Internal Node → Leaf Node → 找到 id=42,共 3 次頁存取
- 有 AHI:hash(42) → Page 7, Slot 3,直接定位,1 次存取
什麼時候該關閉?
AHI 全自動、預設開啟,但高併發下 hash index 的 latch 競爭(btr_search_latch)可能成為瓶頸。如果在 SHOW ENGINE INNODB STATUS 中看到大量 hash index 相關的 latch wait,可以透過 innodb_adaptive_hash_index=OFF 關閉。
Log Buffer
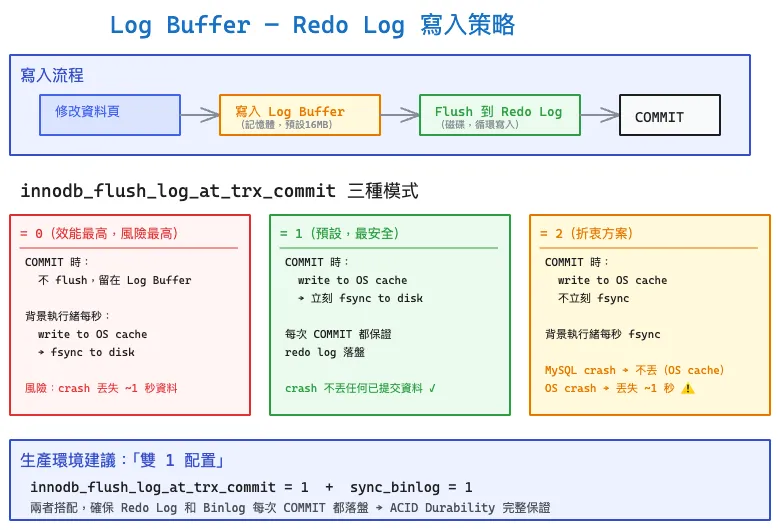
Redo log 不是每次都直接寫磁碟,而是先寫到 Log Buffer(預設 16MB),再依設定決定何時 flush 到磁碟上的 Redo Log 檔案。
寫入流程:修改資料頁 → 寫入 Log Buffer(記憶體)→ flush 到 Redo Log(磁碟)→ COMMIT 完成。
innodb_flush_log_at_trx_commit 三種模式
這個參數決定 COMMIT 時 redo log 的落盤策略,是效能與安全的核心取捨:
| 值 | COMMIT 行為 | 風險 | 效能 |
|---|---|---|---|
| 0 | 不 flush,留在 Log Buffer;背景執行緒每秒 write + fsync | crash 丟失最多 ~1 秒的已提交資料 | 最高 |
| 1(預設) | 立刻 write to OS cache → 立刻 fsync to disk | crash 不丟任何已提交資料 | 最低 |
| 2 | write to OS cache,不立刻 fsync;背景執行緒每秒 fsync | MySQL crash 不丟(資料在 OS cache);OS crash 丟失 ~1 秒 | 中等 |
- = 0:效能最高但風險最大。MySQL crash 或 OS crash 都可能丟資料,只適合可以容忍丟失的場景(如 session 暫存資料)
- = 1:每次 COMMIT 都 fsync,保證 Durability。這是 ACID 合規的唯一選擇
- = 2:折衷方案。MySQL 自己掛掉不丟資料(因為已經 write 到 OS page cache),但如果整台機器斷電(OS crash),OS cache 中還沒 fsync 的部分就丟了
生產環境建議:雙 1 配置
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
兩者搭配,確保 Redo Log 和 Binlog 每次 COMMIT 都落盤,完整保證 ACID Durability。代價是每次 COMMIT 兩次 fsync,可透過 Group Commit 機制(多個交易合併一次 fsync)來緩解效能影響。
更多關於 Redo Log 的循環寫入、Undo Log 與兩階段提交的細節,詳見 InnoDB Logs。
一條 UPDATE 的完整旅程
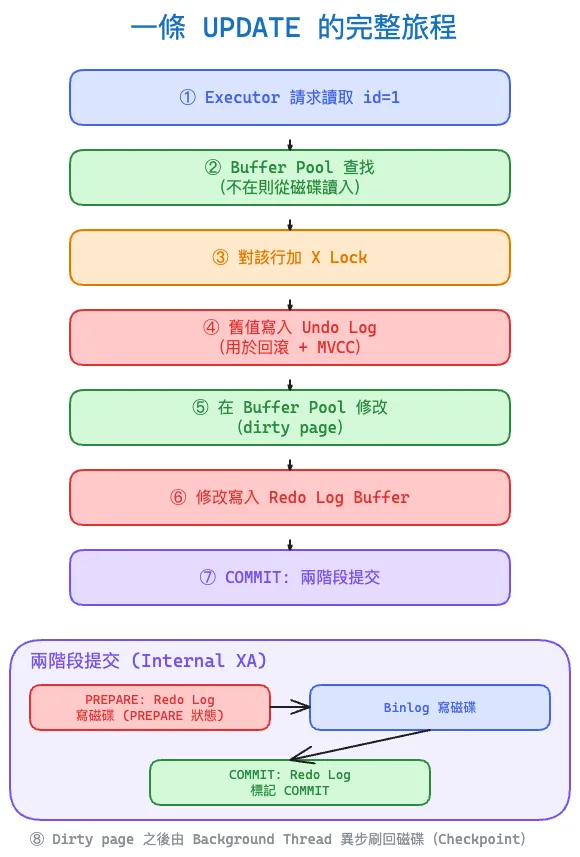
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
- Executor 透過 Handler API 要求 InnoDB 讀取
id=1的資料頁 - InnoDB 檢查 Buffer Pool,不在就從磁碟讀入(會觸發 Change Buffer merge)
- 對該行加 X lock(排他鎖)
- 把舊值寫入 Undo Log(用於回滾與 MVCC)
- 在 Buffer Pool 中修改頁面(此時頁面變成 dirty page)
- 把修改寫入 Redo Log Buffer
- 如果是 COMMIT:
- Redo Log Buffer flush 到磁碟(WAL,Write-Ahead Logging)
- Binlog 寫入磁碟
- 兩者透過 內部 XA(兩階段提交) 保證一致(見 InnoDB Logs)
- Dirty page 之後由 Background Thread 非同步刷回磁碟(checkpoint)
重點:資料頁不需要在 COMMIT 時寫回磁碟。崩潰後靠 redo log 重播就能恢復,這就是 WAL 的核心思想——把隨機寫轉成順序寫。
連線管理
每個客戶端連線在 MySQL 內部對應一個 thread。max_connections 預設 151,超過會報 Too many connections。
生產環境的做法:
- 應用層用連線池(HikariCP、Druid),控制最大連線數
- 中間層用 ProxySQL 或 MySQL Router 做連線多工、讀寫分離
wait_timeout(預設 28800 秒 = 8 小時)控制閒置連線自動斷開
長連線的陷阱:MySQL 的某些操作(如大排序、大 JOIN)會在連線的 thread 記憶體上分配臨時空間,連線不斷開就不釋放,時間久了 OOM。解法是定期執行 mysql_reset_connection(5.7+)重置連線狀態但不重建 TCP。