InnoDB 的三種 Log
深入解析 Redo Log、Undo Log、Binlog 各自的角色、寫入時機、以及三者如何透過兩階段提交保證 crash-safe
為什麼需要這麼多 Log
MySQL 有三種核心 log,各自解決不同的問題:
| Log | 層級 | 保證的特性 | 一句話 |
|---|---|---|---|
| Redo Log | InnoDB 引擎層 | Durability | COMMIT 後即使斷電,資料也能恢復 |
| Undo Log | InnoDB 引擎層 | Atomicity + Isolation | ROLLBACK 時還原資料;MVCC 讀取歷史版本 |
| Binlog | Server 層 | Replication + Point-in-Time Recovery | 主從複製;資料庫恢復到任意時間點 |
三者不能互相取代。Redo Log 管 crash recovery,Undo Log 管回滾與 MVCC,Binlog 管複製與備份。少了任何一個,系統就有缺口。
Redo Log
WAL:先寫日誌,再寫資料
InnoDB 不會在每次修改時把 dirty page 立刻刷回磁碟——隨機寫太慢。它採用 Write-Ahead Logging(WAL):先把「改了什麼」順序寫到 redo log,COMMIT 時確保 redo log 已落盤,dirty page 之後再慢慢刷。
崩潰重啟時,InnoDB 比對 redo log 與資料頁的 LSN(Log Sequence Number),把已 COMMIT 但尚未刷盤的修改重新 apply——這就是 crash recovery,也是 durability 的基石。
物理日誌 vs 邏輯日誌
Redo log 是物理日誌:記錄的是「在某個 tablespace 的某個 page 的某個 offset 寫了什麼 bytes」。好處是 replay 不需要理解 SQL 語義,直接覆蓋即可,速度極快。
相較之下,binlog 是邏輯日誌:記錄的是 SQL 語句或行變化,replay 要重新走一遍邏輯。
固定大小、循環寫入
Redo log 由一組固定大小的檔案組成(預設 2 個,每個 48MB,8.0.30 起預設 100MB)。兩個指標管理空間:
- write pos:當前寫入位置,向前推進
- checkpoint:已刷盤的 dirty page 對應的位置,向前推進
write pos 追上 checkpoint 時,redo log 滿了,InnoDB 被迫暫停所有寫入,先把 dirty page 刷盤推進 checkpoint——這就是 checkpoint flush,生產環境要避免。
checkpoint write pos
↓ ↓
┌──────────────────────────────────────────────────┐
│ ████████████████ ░░░░░░░░░░░░░░░ │
│ 已 checkpoint 可用空間 待寫入 │
└──────────────────────────────────────────────────┘
← 循環 →
調大 redo log(innodb_redo_log_capacity,8.0.30+)可以容納更多 dirty page 不急著刷,但代價是 crash recovery 時間變長。生產環境常見 1–4GB。
innodb_flush_log_at_trx_commit
這是 redo log 最關鍵的參數,控制 COMMIT 時 redo log 怎麼寫:
| 值 | 行為 | 效能 | 安全 |
|---|---|---|---|
| 1 | 每次 COMMIT 都 write() + fsync() 到磁碟 | 最慢 | 最安全 |
| 0 | 寫到 Log Buffer,每秒由後台 thread flush | 最快 | 最多丟 1 秒 |
| 2 | 每次 COMMIT 都 write() 到 OS page cache,每秒 fsync | 中等 | OS crash 才丟 |
生產環境用 1。設成 0 或 2 代表你接受斷電丟資料——MySQL 程序 crash 不會丟(因為在 OS page cache),但整台機器斷電會。
Group Commit
設 innodb_flush_log_at_trx_commit = 1 每次 COMMIT 都 fsync 太慢。InnoDB 用 group commit 改善:多個交易的 redo log 合併成一次 fsync。Leader thread 收集同時 COMMIT 的交易,一次 fsync 搞定,其他 thread 等通知即可。這讓 TPS 從受限於 fsync IOPS 變成受限於「每秒能做幾次 group fsync」。
Undo Log
回滾保證原子性
每次修改行資料前,InnoDB 先把舊值寫進 undo log。如果交易 ROLLBACK,順著 undo log 把每一步改動逆向回復。這就是原子性的實現——「全做或全不做」的「全不做」靠的是 undo log。
版本鏈支撐 MVCC
Undo log 不只服務回滾,還為 MVCC 提供歷史版本。每一行的隱藏欄位 DB_ROLL_PTR 指向上一個版本在 undo log 中的位置,形成一條版本鏈。Read View 順著鏈往回找,直到找到對自己可見的版本。詳見 MVCC。
Undo Log 的類型
| 類型 | 觸發 | 用途 | 回收時機 |
|---|---|---|---|
| Insert Undo | INSERT | 回滾時刪除新插入的行 | 交易 COMMIT 後立刻回收 |
| Update Undo | UPDATE/DELETE | 回滾 + MVCC 歷史版本 | 沒有任何 Read View 需要時回收 |
Insert undo 可以立刻回收是因為新插入的行不會有其他交易需要讀它的「更舊版本」(不存在)。Update undo 可能被其他交易的 MVCC 讀取,必須等到全域最老的活躍 Read View 都不再需要它時才由 purge thread 清理。
長交易的代價:一筆跑了 10 分鐘的交易會讓 10 分鐘內所有 update undo 都無法清理,undo tablespace 持續膨脹。這是生產環境要避免長交易的主要原因之一。
Binlog
Server 層的邏輯日誌
Binlog 不屬於 InnoDB,是 MySQL Server 層的日誌。所有引擎的修改都會寫 binlog(MyISAM 也會)。它記錄的是邏輯變化,有三種格式:
| 格式 | 記錄內容 | 優點 | 缺點 |
|---|---|---|---|
| STATEMENT | 原始 SQL | 日誌小 | 非確定性函數(NOW()、RAND())可能主從不一致 |
| ROW | 每行變化的 before/after | 確定性、安全 | 日誌量大 |
| MIXED | 預設 STATEMENT,不安全時自動切 ROW | 折衷 | 行為不可預測 |
生產環境用 ROW。STATEMENT 在 RC 隔離等級下可能產生主從不一致(因為 RC 不保證範圍查詢的順序),ROW 格式不受此影響。
Binlog 的兩大用途
- 主從複製:Slave 拉取 Master 的 binlog,replay 維持資料同步。見 Replication。
- Point-in-Time Recovery(PITR):全量備份 + binlog 可以把資料庫恢復到任意秒級的時間點。
sync_binlog
類似 redo log 的 flush 策略:
| 值 | 行為 | 安全 |
|---|---|---|
| 1 | 每次 COMMIT 都 fsync binlog | 最安全 |
| 0 | 由 OS 決定何時 flush | 最快但可能丟 |
| N | 每 N 次 COMMIT fsync 一次 | 折衷 |
生產環境用 1,搭配 innodb_flush_log_at_trx_commit = 1,俗稱「雙 1 配置」。
兩階段提交(Internal XA)
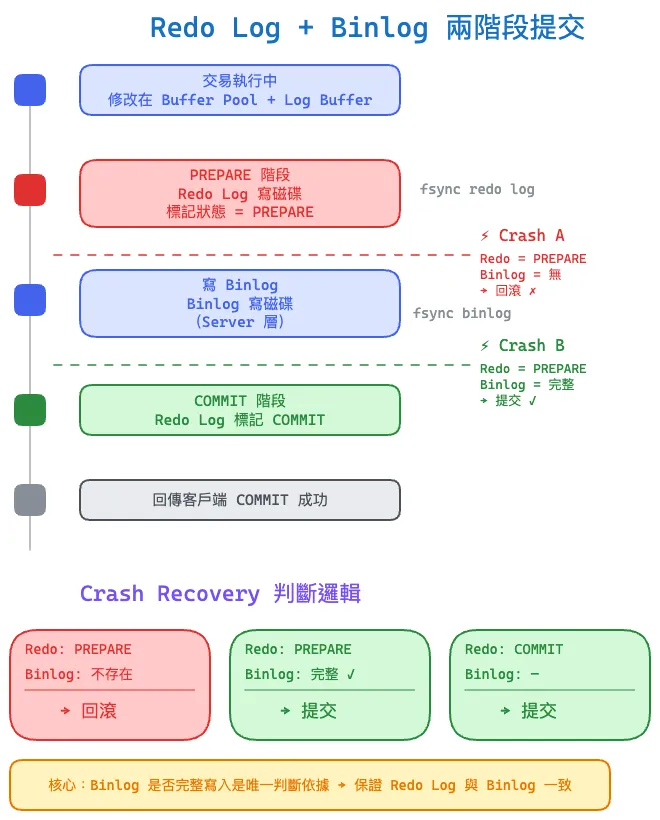
問題:Redo Log 和 Binlog 怎麼保持一致
Redo log 是 InnoDB 的,binlog 是 Server 層的,兩份日誌獨立寫入。如果只寫了 redo log 沒寫 binlog(或反過來),crash recovery 後本機資料和 slave 資料就會不一致。
解法:兩階段提交
InnoDB 把 COMMIT 拆成兩步:
1. PREPARE 階段
- 把 redo log 寫入磁碟,標記為 PREPARE 狀態
2. COMMIT 階段
- 把 binlog 寫入磁碟
- 在 redo log 中寫入 COMMIT 標記
Crash recovery 時的判斷邏輯:
| Redo Log 狀態 | Binlog 是否完整 | 決策 |
|---|---|---|
| PREPARE | 有完整 binlog | 提交(binlog 已寫,slave 可能已收到) |
| PREPARE | 無 binlog | 回滾(兩邊都還沒生效) |
| COMMIT | — | 提交(已正常完成) |
關鍵在於:binlog 寫入是原子的(有 checksum),所以可以明確判斷「有沒有完整寫入」。這個機制保證了 redo log 和 binlog 的邏輯一致,也就保證了本機恢復和 slave 複製的一致。
Binlog Group Commit
MySQL 5.6 開始,binlog 的兩階段提交也引入 group commit,分三個階段:
- Flush stage:多個交易的 binlog 合併寫入 OS page cache
- Sync stage:一次 fsync 把這批 binlog 刷盤
- Commit stage:在各自的 redo log 寫 COMMIT 標記
一次 fsync 搞定多個交易的 binlog,大幅提升了「雙 1 配置」下的吞吐。
三種 Log 的對比
| 特性 | Redo Log | Undo Log | Binlog |
|---|---|---|---|
| 所屬 | InnoDB 引擎層 | InnoDB 引擎層 | Server 層 |
| 日誌類型 | 物理日誌 | 邏輯日誌 | 邏輯日誌 |
| 記錄內容 | 頁面的物理變更 | 行的舊值(回滾用) | SQL 或行變化 |
| 寫入時機 | 交易執行中持續寫入 | 修改行之前 | COMMIT 時 |
| 大小 | 固定大小、循環寫入 | 動態增長、purge 回收 | 追加寫入、按時間/大小切檔 |
| 保證的特性 | Durability | Atomicity + Isolation | Replication + PITR |
| crash recovery | 重播已 COMMIT 的修改 | 回滾未 COMMIT 的修改 | 不參與 InnoDB recovery |
Crash Recovery 的完整流程
MySQL 異常重啟後,InnoDB 的恢復分兩步:
- Redo(前滾):掃描 redo log,把所有 LSN 大於資料頁 LSN 的修改重新 apply,不管交易有沒有 COMMIT——先讓資料頁回到 crash 前的狀態。
- Undo(回滾):檢查 undo log,找到所有在 crash 時仍處於 active 狀態(既沒有 COMMIT 也沒有 PREPARE + binlog)的交易,用 undo log 回滾。
前滾保證了 durability(已 COMMIT 的不丟),回滾保證了 atomicity(未 COMMIT 的不留)。兩者配合才是完整的 crash-safe。
生產環境的 Log 配置建議
[mysqld]
# 雙 1 配置 — durability 最高保證
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
# Redo log 大小 — 根據寫入量調整,避免頻繁 checkpoint
innodb_redo_log_capacity = 2G # 8.0.30+
# innodb_log_file_size = 1G # 8.0.30 以前
# innodb_log_files_in_group = 2 # 8.0.30 以前
# Binlog
binlog_format = ROW
binlog_expire_logs_seconds = 604800 # 保留 7 天
max_binlog_size = 256M # 單檔大小上限
# Undo
innodb_undo_tablespaces = 2 # 分離 undo tablespace,方便 truncate
innodb_max_undo_log_size = 1G
innodb_undo_log_truncate = ON # 自動 truncate 過大的 undo tablespace
總結:哪個 Log 保證哪個特性
Atomicity ← Undo Log(回滾未完成的交易)
Durability ← Redo Log(WAL,crash 後重播)
Isolation ← Undo Log(MVCC 版本鏈)+ Locks
Replication ← Binlog(主從複製)
PITR ← Binlog(時間點恢復)
Crash-Safe ← Redo Log + Binlog 兩階段提交