主從複製與高可用
介紹 MySQL 主從複製的原理、三種 Binlog 格式、半同步複製、GTID、Group Replication 與常見高可用方案
複製的核心:Binlog
MySQL 的主從複製建立在 Binlog 之上。Master 把所有修改寫進 binlog,Slave 拉取 binlog 並重播,藉此保持資料同步。Binlog 是 Server 層的邏輯日誌,與 InnoDB 的 redo log 無關——這也是為什麼複製是 MySQL 層級的功能,不限定特定引擎。
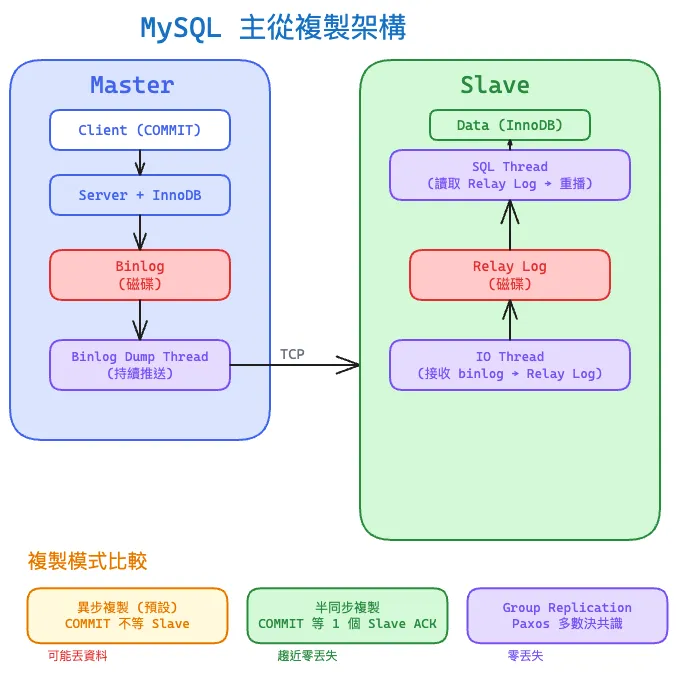
複製的三個 Thread
Master Slave
┌─────────────┐ ┌─────────────────┐
│ Binlog │ ──────────────→ │ IO Thread │
│ Dump Thread│ TCP 傳輸 │ (寫入 Relay Log) │
└─────────────┘ ├─────────────────┤
│ SQL Thread │
│ (重播 Relay Log) │
└─────────────────┘
- Binlog Dump Thread(Master):Slave 連線後,Master 啟動此 thread 持續把 binlog event 推送給 Slave。
- IO Thread(Slave):接收 binlog event,寫入本地的 Relay Log。
- SQL Thread(Slave):讀取 Relay Log 並逐事件重播。
IO Thread 和 SQL Thread 是解耦的——即使 SQL Thread 重播慢,IO Thread 仍持續接收,Relay Log 當 buffer。
異步複製(Async Replication)— 預設
Master COMMIT 後立即回傳客戶端,不等 Slave 確認。最快但風險最高:Master 掛了如果 Slave 還沒拉到最新的 binlog,資料就丟了。
Master COMMIT → 回傳客戶端 → (異步)推 binlog → Slave
↑ 不等 Slave
延遲來源:網路傳輸 + Slave IO Thread 寫 Relay Log + SQL Thread 重播。生產環境正常延遲秒級,寫入量大或大交易時可能分鐘級。
半同步複製(Semi-Synchronous Replication)
MySQL 5.5 引入,5.7 改良為 loss-less semi-sync。Master 在 COMMIT 時等待至少一個 Slave 確認已收到 binlog(寫到 Relay Log),才回傳客戶端。
Master COMMIT → 等 Slave ACK → 回傳客戶端
↑
Slave 收到 binlog 寫入 Relay Log 後 ACK
AFTER_COMMIT vs AFTER_SYNC
| 模式 | 時機 | 風險 |
|---|---|---|
| AFTER_COMMIT | Master commit 後才等 Slave ACK | 其他 Session 可能讀到 Slave 還沒有的資料 |
| AFTER_SYNC | Master 寫 binlog 後、commit 前等 | 無損,Master 和 Slave 一致 |
5.7 預設 AFTER_SYNC(rpl_semi_sync_master_wait_point = AFTER_SYNC),稱為 loss-less semi-sync。
退化機制
如果 Slave 長時間不回 ACK(超過 rpl_semi_sync_master_timeout,預設 10 秒),Master 自動退化為異步複製,避免卡住所有寫入。Slave 追上後自動恢復半同步。
GTID(Global Transaction ID)
MySQL 5.6 引入。每個交易有全域唯一的 ID:source_id:transaction_id(例如 3E11FA47-71CA-11E1-9E33-C80AA9429562:23)。
解決了什麼問題
傳統複製用 binlog 檔名 + position 定位同步進度,Slave 切換 Master 時要手動計算 position——容易算錯、出錯難排。GTID 讓 Slave 記錄「我已經執行過哪些 GTID」,切換 Master 只要告訴新 Master「我有這些 GTID,給我剩下的」。
-- 啟用 GTID
[mysqld]
gtid_mode = ON
enforce_gtid_consistency = ON
GTID 的限制
CREATE TABLE ... SELECT不被允許(一條語句包含 DDL + DML,無法只分配一個 GTID)- 臨時表的某些操作受限
- 不能在交易中混合 InnoDB 和 MyISAM
生產環境建議一律開啟 GTID,除非有歷史包袱。
並行複製(Multi-Threaded Slave)
單一 SQL Thread 重播是複製延遲的最大瓶頸。MySQL 5.6 開始支援多 SQL Worker Thread 並行重播:
| 版本 | 並行粒度 | 效果 |
|---|---|---|
| 5.6 | 按 database 並行 | 單庫場景沒用 |
| 5.7 | 按 logical clock(同 group commit 的交易並行) | 大幅改善 |
| 8.0 | WRITESET(基於寫入行的衝突偵測) | 最細粒度,效果最好 |
-- 8.0 建議設定
[mysqld]
replica_parallel_type = LOGICAL_CLOCK -- 8.0.26+
replica_parallel_workers = 8 -- 依 CPU 核心數調
binlog_transaction_dependency_tracking = WRITESET
Group Replication
MySQL 5.7.17 引入的原生高可用方案。多個節點組成 group,透過 Paxos(變體 XCom) 共識協議保證一致性。
架構
- 每個節點都有完整資料,都能處理讀取
- 寫入送到 primary 節點(single-primary mode)或任意節點(multi-primary mode)
- 交易在 group 內走共識,多數節點確認後才 commit
Single-Primary vs Multi-Primary
| 模式 | 寫入節點 | 衝突處理 | 適用 |
|---|---|---|---|
| Single-Primary | 一個 primary | 不需要 | 大多數場景(推薦) |
| Multi-Primary | 所有節點 | 交易可能 rollback | 需要多點寫入的場景 |
Multi-primary 下兩個節點同時修改同一行,後 certify 的交易會被 rollback。衝突率高時效能反而更差。
容錯
和 Raft/Paxos 一樣是多數決:3 節點容 1 掛、5 節點容 2 掛。節點數用奇數。
InnoDB Cluster
MySQL 官方的「一鍵高可用」方案,整合了三個元件:
┌─────────────────────────────────────┐
│ MySQL Router │ ← 應用層連這裡
│ (讀寫分離、自動 failover 路由) │
├─────────────────────────────────────┤
│ Group Replication │ ← 資料層共識
│ node1(primary) node2 node3 │
├─────────────────────────────────────┤
│ MySQL Shell │ ← 管理工具
│ (部署、監控、failover 管理) │
└─────────────────────────────────────┘
- Group Replication:資料同步與共識
- MySQL Router:中間層代理,自動偵測 primary 變更並路由
- MySQL Shell:adminAPI 管理 cluster 生命週期
Primary 掛了 Group Replication 自動選新 primary,Router 自動切換路由,應用不需改程式碼。
常見高可用方案比較
| 方案 | RPO | RTO | 複雜度 | 適用 |
|---|---|---|---|---|
| 異步複製 + MHA | 可能丟數據 | 秒到分鐘 | 中 | 能接受少量丟失 |
| 半同步複製 + MHA/Orchestrator | 趨近零 | 秒到分鐘 | 中高 | 不能丟數據 |
| InnoDB Cluster | 零(多數決) | 秒級 | 中 | 新專案推薦 |
| InnoDB ClusterSet | 跨 region | 分鐘級 | 高 | 災備 |
| Vitess / PlanetScale | 依配置 | 自動 | 高 | 超大規模 sharding |
複製延遲的監控與排查
-- 查看 Slave 狀態
SHOW REPLICA STATUS\G
-- 關注:Seconds_Behind_Source、Relay_Log_Space、
-- Retrieved_Gtid_Set vs Executed_Gtid_Set
-- 精確延遲監控(pt-heartbeat 或自建)
-- Master 定時寫入 timestamp,Slave 讀取比對
延遲常見原因:
- 大交易:一筆 DELETE 百萬行,Slave 也要重播百萬行
- DDL:ALTER TABLE 在 Slave 上單線程執行
- Slave 硬體瓶頸:磁碟 IO、CPU
- 長交易持有鎖:阻塞 SQL Thread 的重播
最佳實踐:大刪除拆批次、DDL 用 pt-online-schema-change 或 gh-ost、Slave 用 SSD、開啟並行複製。
Binlog 與 Replication 的 Log 關係
Durability ← Redo Log(本機 crash-safe)
Replication ← Binlog(主從資料同步)
Crash-Safe ← Redo Log + Binlog 兩階段提交(本機一致性)
HA ← Binlog + Semi-Sync / Group Replication(跨節點一致性)
Redo log 只管本機,binlog 管跨機器。兩者透過兩階段提交保證本機一致,再靠半同步或 Group Replication 保證跨節點一致。