WAL 與 Crash Recovery
深入解析 PostgreSQL 的 WAL 機制、Checkpoint、full_page_writes,以及 crash recovery 的完整流程
一套 WAL 打天下
MySQL 需要兩套日誌互相配合——Redo Log(InnoDB 引擎層,保證 durability)和 Binlog(Server 層,保證 replication),兩者之間靠兩階段提交保持一致。
PostgreSQL 只有一套 WAL,同時負責:
- Crash Recovery:重啟後重播 WAL 恢復資料
- Streaming Replication:Standby 拉取 WAL 保持同步
- Point-in-Time Recovery(PITR):全量備份 + WAL archive 恢復到任意時間點
一套日誌做三件事,架構比 MySQL 乾淨,也不需要兩階段提交。
WAL 的基本原理
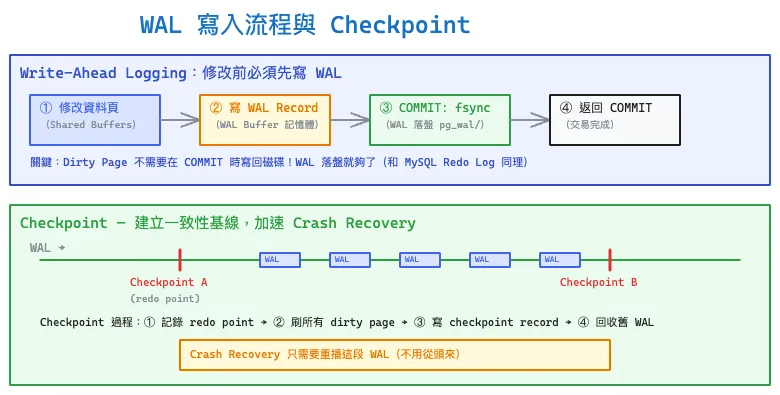
和 MySQL 的 Redo Log 一樣是 Write-Ahead Logging:任何資料頁的修改,必須先把對應的 WAL record 寫入磁碟,然後才能把 dirty page 寫回磁碟。
上圖展示完整的寫入流程:① 修改 Shared Buffers 中的資料頁 → ② 將 WAL record 寫入 WAL Buffer(記憶體)→ ③ COMMIT 時 fsync WAL 到磁碟(pg_wal/)→ ④ 返回 COMMIT 成功。Dirty page 不需要在 COMMIT 時寫回磁碟——之後由 Checkpoint 或 BGWriter 非同步刷盤。
圖的下半部說明 Checkpoint 機制:Checkpoint 在 WAL 中建立一個一致性基線(redo point),將所有 dirty page 刷回磁碟後寫入 checkpoint record。Crash Recovery 只需要從最近的 checkpoint 開始重播 WAL,之前的 WAL 可以安全回收,不需要從頭來。
LSN(Log Sequence Number)
WAL 中每個 record 的位置用 LSN 標記——一個持續遞增的 64-bit 整數,代表在 WAL 串流中的 byte offset。每個資料頁的 header 也記錄了最後一次修改對應的 LSN。Crash recovery 時比對兩者就知道哪些頁面需要重播。
-- 查看當前 WAL 寫入位置
SELECT pg_current_wal_lsn();
-- 查看當前 WAL flush 位置(已 fsync)
SELECT pg_current_wal_flush_lsn();
-- 兩者差距 = WAL Buffer 中尚未 flush 的量
SELECT pg_current_wal_lsn() - pg_current_wal_flush_lsn() AS pending_bytes;
WAL 檔案結構
WAL 存在 $PGDATA/pg_wal/ 目錄下,每個檔案預設 16MB(可在 initdb 時用 --wal-segsize 調整)。檔案名是 24 位 hex,包含 timeline + segment number。
pg_wal/
├── 000000010000000000000001
├── 000000010000000000000002
├── 000000010000000000000003
└── ...
舊的 WAL 檔案會被回收再利用(rename),不是刪掉重建。max_wal_size 控制 WAL 佔用的磁碟上限(預設 1GB),超過時觸發 checkpoint 加速回收。
COMMIT 時 WAL 的 flush 策略
synchronous_commit
類似 MySQL 的 innodb_flush_log_at_trx_commit,控制 COMMIT 時 WAL 是否要 fsync:
| 值 | 行為 | 安全 | 效能 |
|---|---|---|---|
on(預設) | COMMIT 時 WAL flush + fsync 到磁碟 | 最安全 | 最慢 |
off | COMMIT 立即返回,WAL 由 WAL Writer 延遲 flush | 最多丟 wal_writer_delay(預設 200ms)的交易 | 最快 |
remote_write | 等 WAL 送到 Standby 的 OS cache | 網路斷不丟 | 中等 |
remote_apply | 等 Standby apply 完 WAL | 最強一致 | 最慢 |
synchronous_commit = off 不會導致資料不一致——crash 後資料庫仍然一致,只是最近幾百毫秒的交易可能不見。對可接受小量丟失的場景(log、metrics)很有用,而且可以 per-transaction 設定:
SET LOCAL synchronous_commit = off;
INSERT INTO logs (...) VALUES (...);
COMMIT; -- 不等 fsync,快速返回
這是 PostgreSQL 比 MySQL 靈活的地方——MySQL 的 innodb_flush_log_at_trx_commit 是 global/session 級別,做不到 per-transaction。
Checkpoint
為什麼需要 Checkpoint
WAL 是追加寫入、會持續增長。如果 crash recovery 必須從頭重播所有 WAL,恢復時間會隨 WAL 量線性增加。Checkpoint 的作用是建立一個已知的一致性基線:把所有 dirty page 刷回磁碟,然後在 WAL 中寫一個 checkpoint record。之後 crash recovery 只需要從最近的 checkpoint 開始重播,之前的 WAL 可以安全回收。
Checkpoint 的過程
- 記錄當前 WAL 位置(checkpoint 的 redo point)
- 把所有 dirty page flush 到磁碟
- 在 WAL 中寫一個 checkpoint record
- 更新
pg_control檔案(記錄最新的 checkpoint 位置) - 回收 redo point 之前的舊 WAL 檔案
觸發時機
| 條件 | 參數 | 預設 |
|---|---|---|
| 時間間隔 | checkpoint_timeout | 5 分鐘 |
| WAL 量達到上限 | max_wal_size | 1 GB |
| 手動觸發 | CHECKPOINT 命令 | — |
| 關閉資料庫 | 自動 | — |
checkpoint_completion_target
Checkpoint 會產生大量 IO。為了避免 IO 尖峰影響正常查詢,PostgreSQL 會把刷 dirty page 的動作平均分散在兩次 checkpoint 之間。checkpoint_completion_target(預設 0.9)表示在下次 checkpoint 前的 90% 時間內完成刷盤。
full_page_writes
Partial Write 問題
OS 寫一個 8KB 的 PostgreSQL page 不是原子的——可能寫到一半斷電,磁碟上留下半新半舊的頁面(torn page)。WAL record 記錄的是 diff(差異),如果基礎頁面本身就壞了,重播 diff 會得到錯誤結果。
解法
full_page_writes = on(預設開啟):每次 checkpoint 後,第一次修改某個 page 時,把整個 page 的完整內容寫進 WAL(稱為 full-page image / FPI)。之後同一 checkpoint 週期內再修改同一 page 只寫 diff。
Crash recovery 時,如果遇到 torn page,用 WAL 中的 full-page image 覆蓋整個 page,再 apply 後續的 diff,就能保證正確。
代價:WAL 體積膨脹(checkpoint 後的第一波寫入特別大)。可以搭配 wal_compression = on(PG 15+)壓縮 FPI 減少 WAL 量。
MySQL 怎麼解決同樣的問題
InnoDB 有 doublewrite buffer:寫 dirty page 前先寫到 doublewrite 區域,再寫到實際位置。如果實際位置 torn,用 doublewrite 的副本覆蓋。效果類似但機制不同。
Crash Recovery 的流程
PostgreSQL 異常重啟後:
- Postmaster 讀取
pg_control,發現上次不是 clean shutdown - 找到最近的 checkpoint 位置(redo point)
- 從 redo point 開始順序重播 WAL:
- 對每個 WAL record,檢查目標 page 的 LSN
- 如果 page LSN < record LSN → apply(頁面比 WAL 舊,需要更新)
- 如果 page LSN >= record LSN → skip(頁面已經包含這個修改)
- 重播完所有 WAL 後,資料庫狀態回到 crash 前的最後一致性點
- 所有未 COMMIT 的交易自動標記為 aborted(不需要像 MySQL 那樣用 undo log 回滾)
第 5 步是 PostgreSQL 和 MySQL 的關鍵差異:PostgreSQL 不需要 undo log 做回滾。未 COMMIT 的交易寫入的 tuple 仍然在磁碟上,但 xmin 對應的交易狀態是 aborted,MVCC 會自動忽略它們,之後由 VACUUM 清理。
WAL 相關的關鍵參數
# WAL 基本設定
wal_level = replica # minimal / replica / logical
max_wal_size = 2GB # checkpoint 觸發閾值
min_wal_size = 80MB # 保留的最小 WAL 量
wal_compression = on # 壓縮 full-page image(PG 15+)
# 持久性
synchronous_commit = on # COMMIT 是否等 fsync
fsync = on # 永遠不要關!關了等於禁用 WAL 保護
full_page_writes = on # 防止 torn page
# Checkpoint
checkpoint_timeout = 5min
checkpoint_completion_target = 0.9
# WAL Writer
wal_writer_delay = 200ms # WAL Writer 的 flush 間隔
# 歸檔(PITR 用)
archive_mode = on
archive_command = 'cp %p /archive/%f'
fsync = off 是唯一一個你永遠不應該關的參數。關掉代表 OS 想什麼時候 flush 就什麼時候 flush,斷電後資料庫可能完全損壞且無法恢復。
WAL vs MySQL 的 Redo Log + Binlog
| 面向 | PostgreSQL WAL | MySQL Redo Log + Binlog |
|---|---|---|
| 套數 | 一套 | 兩套 |
| 一致性 | 天生一致 | 需要兩階段提交 |
| Crash Recovery | WAL 重播 | Redo 前滾 + Undo 回滾 |
| Replication | 同一套 WAL | Binlog(不同於 Redo Log) |
| 回滾機制 | 不需要回滾(標記 aborted) | Undo Log 逆向回復 |
| PITR | WAL archive | Binlog |
| 日誌格式 | 物理(page diff + FPI) | Redo 物理 + Binlog 邏輯 |
PostgreSQL 的「一套 WAL 打天下」更簡潔,但 MySQL 的 Binlog 在邏輯複製(row-based)上比 WAL 的物理複製更靈活——這也是為什麼 PostgreSQL 後來又加了 Logical Replication。