Prefetch 調優
深入分析 prefetch_count 的運作原理,以及在不同場景(CPU 密集、IO 密集、多 Consumer)下的最佳調校策略
沒有 prefetch 時發生什麼事
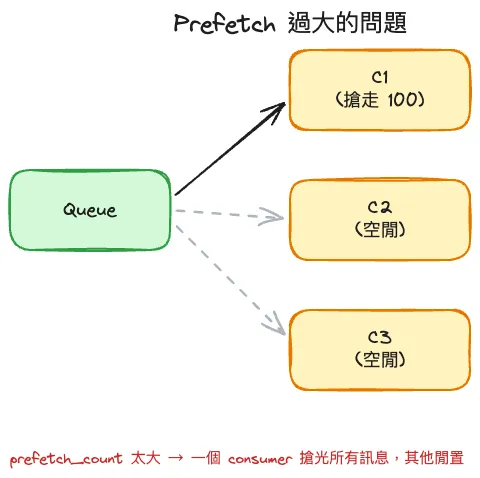
Consumer 沒設 QoS 時,broker 會用 round-robin 把訊息一筆一筆輪流丟給每個 consumer,不管對方處不處理得完。這帶來兩個問題:broker 會一次把大量訊息推到 consumer 的 socket buffer,後面幾千筆堆在那邊等著;而且 round-robin 只看順位不看負載,慢的 consumer 被塞滿、快的乾瞪眼,整體吞吐被最慢那台拖累。更糟的是慢 consumer crash 時那堆 unacked 訊息全部 requeue,對其他 consumer 造成尖峰衝擊。
Prefetch 用一條規則改寫派送邏輯:consumer 手上未 ACK 的訊息達到 prefetch_count 時,broker 就不再推新的。等於在每個 consumer 前面裝了水閘,迫使 broker 去找還有額度的其他 consumer。
basic.qos 的三個參數
| 參數 | 作用 |
|---|---|
prefetch_count | 最多同時未 ACK 的訊息數量 |
prefetch_size | 最多同時未 ACK 的資料總量(幾乎沒人用) |
global | 限制範圍:per-channel 還是 per-consumer |
prefetch_size 大部分客戶端沒有完整實作,忽略即可。真正容易踩坑的是 global,它在 AMQP 規範與 RabbitMQ 實作之間剛好相反:
| global | AMQP 規範 | RabbitMQ 實作 |
|---|---|---|
| false | per-channel | per-consumer(預設) |
| true | per-connection | per-channel |
RabbitMQ 預設 global=false,限制的是每個 consumer。同一 channel 上註冊 3 個 consumer、prefetch_count=10,總 unacked 上限是 30 不是 10。
prefetch_count = 1:公平分發
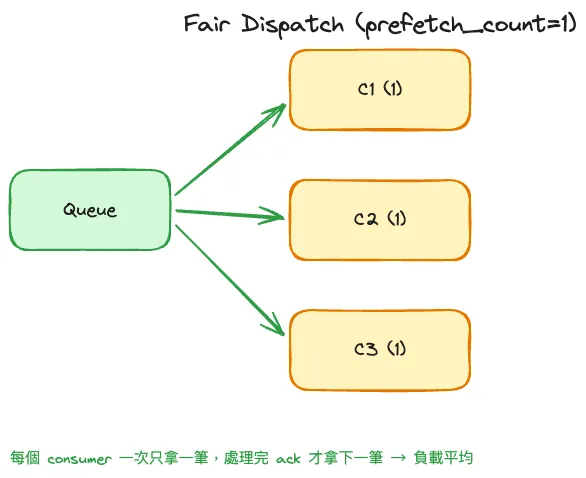
await channel.set_qos(prefetch_count=1)
每個 consumer 同時間最多 1 筆未 ACK,處理完才拿下一筆。慢的自然少、快的多幹活,徹底解決分配不均。代價是每筆都要一次完整 round-trip,如果 RTT 5 ms、處理只要 1 ms,consumer 大部分時間都在等網路。所以 prefetch=1 只適合處理時間遠大於網路延遲的場景:圖片處理、PDF 轉檔、AI 推論、外部 API 呼叫。
太大的代價
看到吞吐量低就一路往上加到 1000、10000 的誘惑很強,但太大會有四個問題:記憶體壓力(每筆 unacked 都佔空間,payload 大容易 OOM)、分配不均回魂(一個 consumer 抓走一堆別人沒事做)、crash 時一次 requeue 幾千筆衝擊其他 consumer、rolling restart 或 scale out 時訊息很難均勻流向新 consumer。
原則是:找到管線飽和的甜蜜點就停手。
不同場景的建議值
| 場景 | prefetch_count | 原因 |
|---|---|---|
| 每筆處理 > 1 秒 | 1 ~ 5 | 分配要夠公平 |
| 每筆處理 100ms ~ 1 秒 | 10 ~ 50 | 平衡公平與吞吐 |
| 每筆處理 < 10ms | 100 ~ 500 | 吞吐量優先 |
| 訊息處理時間變異大 | 偏小 | 避免慢訊息卡住 consumer |
| Consumer 記憶體敏感 | 偏小 | 避免緩衝過多訊息 |
快速估算起點值:
prefetch_count ≈ round_trip_time / processing_time_per_message
RTT 10 ms、每筆處理 50 ms 時 10/50 = 0.2 取 1;每筆處理 1 ms 時 10/1 = 10。這只是起點,真實最佳值要靠壓測。
壓測流程
PerfTest 或自寫腳本皆可。Prefetch 從 1 開始依 1、5、10、50、100、500 指數往上試,每個值跑幾分鐘進入穩定狀態,記錄吞吐量和 P99 延遲。
觀察趨勢:一開始吞吐量線性上升,到某個點後飽和不再上升——那就是管線飽和的臨界點。繼續加 prefetch,P99 延遲會開始惡化,因為訊息在 consumer buffer 排隊等候處理。
取吞吐量飽和、P99 還沒惡化的值,乘 0.8 安全係數作為生產設定。
Prefetch 只對 Manual ACK 有意義
auto_ack=True 時 broker 推送即視為已消費,根本沒有「未 ACK」狀態,prefetch 完全無效。Manual ACK + prefetch + 冪等 consumer 是 RabbitMQ 可靠消費的標準組合。
常見錯誤
- 以為越大越好,踩到記憶體和分配不均陷阱。
- 不知道
global=false是 per-consumer,實際上限比想像多好幾倍。 - Auto ACK 還調 prefetch,白做工。
- 同一 channel 混用處理時間差異很大的 consumer 共用 prefetch——正確做法是按類型拆 channel。